实际上这一部分的很多概念都已经在COMP3354第一章里讲过了。建议你去看看这一部分:
AI, ML 和 DL
这三个词是我们在本节课中会不停使用到的词。
Artificial Intelligence (AI) 为人工智能。人工智能指任何能让机器模仿人类行为的技术。
AI的一个子集叫做 Machine Learning (ML) ,也就是机器学习。机器学习的核心在于 不需要刻意为行为做编程,也就是说我们不需要告诉机器遇到什么规则做什么,而是给机器数据,机器使用统计学方法让它从经验中自我改进。
ML的一个子集,同样包含在AI下 —— 叫做 Deep Learning (DL) ,深度学习。深度学习相比普通机器学习,使用多层神经网络来处理更高维度(更复杂的)数据,实现了图像,语言,音频的处理。可以说最近AI的爆火主要是这方面的突破与创新。
机器学习的动机与定义
机器学习用在哪了?
假如你被微软录用了,你被分配到了MS Office部门负责Outlook的开发,你的上级要求你在Outlook里添加一个模块来主动拦截垃圾邮件。
如果你在上世纪70年代入职,当时无法使用ML计数,那么程序员必须要手动编写成千上万条规则,建立一个巨大的if...then逻辑链条来拦截邮件。例如,包含“抽奖”二字的邮件是垃圾邮件。但是但凡邮件发送人改变了策略,用了编写逻辑之外的方式来传达信息,例如“酬奖”,你的逻辑就不好用了。
但是现在是2026年,你可以选择使用ML算法来实现这样的功能。ML算法是自学习的,因此我们不需要手动编写规则,而是将庞大的数据集交给计算机,喂给算法,算法会自动从中挖掘出数据中隐藏的规律,来自动整理规则。
实际上我们的生活已经离不开ML的应用了。你打开B站刷的视频,搜索引擎的搜索建议,淘宝商品推荐等,几乎全是ML的功劳。
机器学习的定义
Arthur Samuel在1959年显式定义了什么是机器学习。他的定义是:
Field of study that gives computers the ability to learn without being explicitly programmed.
让计算机在没有被显式编程的情况下具备学习能力的研究领域。
这里的关键是不需要显式编程行为。如果你的所谓逻辑是手动写出的if x > 5 then...,那么就不是机器学习。机器学习是机器自己算出来5这个阈值的过程。
但在1998年工程派为代表的Tom Mitchell提出了一个更现代,更严谨的定义:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
我们在COMP3252中说过:
- Task (T): 任务。比如“区分垃圾邮件”。
- Experience (E): 经验。即历史数据,比如“以前收到的 1000 封邮件及其标签”。
- Performance (P): 性能指标。比如“分类的准确率”。
如果一个程序在任务T上的性能P,随着经验E的增加而提高,那么我们就说这个程序正在“学习”。
监督学习
监督学习是目前机器学习应用最广泛的形式。监督学习就像你刷五三。前面有题目,后面有答案。你做一道题就对一下答案。如果做错了,就根据标准答案来修正自己的思路。你的目标当然是在遇到没有答案的考试时,能算出正确的答案。
监督学习也是一样,机器在训练数据集上训练,这些数据都包含 标签(Label) ,用来告诉算法正确方向。
监督学习有两个主要目标类型:
分类问题 (Classification)
分类问题预测的结果是离散的类别。就像选择题ABCD一样,没有中间值。二分类只有两个输出选项,非黑即白,可以想象成将数据点平摊在2D平面上,算法划出一条决策边界,把正类和负类切开。
多分类就是选项大于两个的分类问题。
如果你不知道我在说什么,你去看看这个吧:
回归问题 (Regression)
回归问题不同于分类问题。它输出的是连续的数值。就像填空题一样,答案可以是任何数字。
既然是预测数值,我们无法画一条线来讲数据分开。反之,我们需要根据训练数据画一条线去尽可能穿过数据点。
算法的目标是找到一条线,让它们所有数据点到这条线的距离(偏差)之和最小。这就是最拟合线。
例如,算法根据学习时间来预测考试分数。时间越长,分数通常越高。这是一条连续的趋势线。
无监督学习
如果老师把你的五三答案全部撕掉了,你该如何自我学习?
如果你是学生,你大概率会根据你的答案自己观察,看看能不能发现什么规律。
聚类问题 (Clustering)
你尝试来观察数据的相似性。你把看起来相似的数据点堆在一起,形成团簇 (Cluster)。
而事实是,相似的数据点往往在背后蕴含相同的属性。例如你发现这批人全是西装革履,那么你有理由怀疑他们都是商务人士。如果你发现这批人全穿球衣,那么事实上它们大概率都是运动员。
降维 (Dimensionality Reduction)
但现实世界中数据太复杂,导致收集到的数据维度太高。这些数据不仅计算起来很慢,同时可能很难以理解。因此我们需要把数据压缩到低维空间,同时尽可能保留最重要的信息。
更多有关降维的内容参见这里:
强化学习
强化学习是最接近生物本能的学习方式。在这里,算法不会通过带标签,或不带标签的数据来学习,相反,只有 智能体 (Agent) 和 环境 (Environment) 。智能体通过与环境互动来学习。
强化学习基于下面的循环来进行训练:
- 智能体观察当前状态
- 智能体做出一个动作
- 环境会根据智能体的动作更新,发生变化,并反馈给智能体一个奖励或惩罚。
智能体的目标是通过不断地试错,来找到一套合适的策略,让长期累积的奖励最大化。
强化学习最大的难点在于 延迟反馈 (Delayed Feedback) 。监督学习的反馈是及时的:模型可以直接通过标签来获得反馈。但是在强化学习中,反馈往往不是及时的。
假如机器正在学习如何下国际象棋。它走了一步棋,当时可能觉得平平无奇,甚至在子力有点亏。但这一步棋导致了你在50步之后赢了比赛。模型如何将这些制胜分数分配给它做的不同决策中?
术语与数学符号
下图是一个数据集:
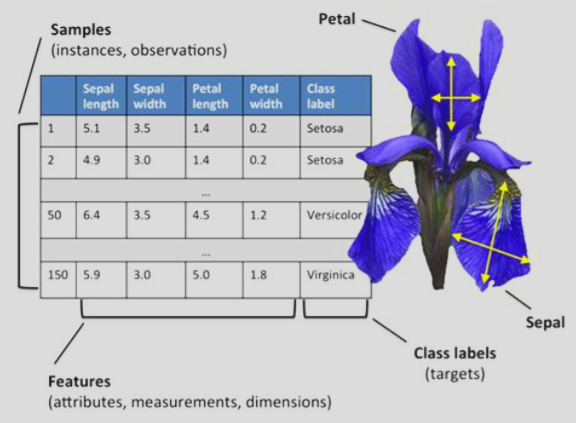
其中,我们定义这些属于来帮助我们在数据集中更准确的描述内容:
每一行代表一朵花。在ML术语中,这叫一个 样本 (Sample), 实例 (Instance) 或者 观测 (Observation)
每一列代表花的一个特征。在ML中,这叫 特征 (Feature),属性 (Attribute) 或 维度 (Dimension)
而最后一列是我们要预测的目标,也就是花的品种。这叫 类别标签 (Class Label)。
为了能够将数据通过数学公式计算,我们需要用严谨的数学方式来表示数据。
我们使用 大写加粗字母 来表示矩阵。通常是$\mathbf{X}$。
对于刚才的数据集,那么 $\mathbf{X}$ 就是一个 $150 \times 4$大小的矩阵,一共150行,4列:
- $n_{samples} = 150$
- $n_{features} = 4$
我们用 小写加粗字母 来表示向量,通常是 $\mathbf{x}$。其中:
行向量 (Row Vector) 代表一朵花的所有数据。这样表示:
$$\mathbf{x}^{(i)}$$
其中右上角的 $(i)$ 不是i次方的意思,而是只“第i个样本”。比如$\mathbf{x}^{(1)}$是第 1 朵花的数据向量 $[5.1, 3.5, 1.4, 0.2]$。
列向量 (Column Vector) 代表某种特征在所有花中的数据:
$$\mathbf{x}_j$$
右下角的 $j$ 代表第 j 个特征。比如 $\mathbf{x}_2$ 代表这 150 朵花所有的“花萼宽度”这一列数据。
而标量 (Scalar) 就是其中的一个格子。我们用 小写斜体 字母来表示具体的数值:
$$x_j^{(i)}$$
代表第 $i$ 个样本的第 $j$ 个特征。比如 $x_1^{(150)}$ 代指“第 150 朵花的第 1 个特征的数值”。
总之, 上标找人,下标找事。上标代表第几个样本,下标代表第几个特征。
机器学习流程
一个完整的ML项目就好比一个流水线,分为三个核心阶段:预处理 (Preprocessing) ,训练/学习 (Learning) 以及 评估 (Evaluation) 。
由于现实世界中的数据往往脏乱差,直接丢进算法通常效果很差。因此我们需要先进行 预处理 。在预处理阶段,我们需要先进行:
- 特征选择 / 特征值缩放
Feature Selection & Scaling
有些特征竖直可能会很大,有些会很小,例如房价与房间数。如果直接计算两个数据的距离,房价会主导一切。这时候我们需要将其缩放到同一个量级。
- 数据降维
Dimensionality Reduction
正如之前提到过的,如果资料和数据太多,我们需要将其压缩成精华。
- 采样 / 数据标注
Sampling
由于是机器学习项目,所以我们需要将手头的数据随即切分成两份,分成 训练集 (Training Set) 和 测试集 (Test Set) 。训练集用来平时做题练习,测试集来做模拟考。
我们不能让模型在训练时看到测试集的数据。一旦偷看就相当于作弊。由于我们通过测试集衡量模型性能,因此模型需要现在训练集上进行训练,然后在测试集上验证。
随后,我们进行学习与训练。
这个时候我们挑选一个模型,让它在训练集上学习。这里有两个概念需要理解:
- 交叉验证 (Cross-Validation)
如果我们想要在训练的时候直到自己学的怎么样,我们能不能用训练集?由于测试集是留到期末的,因此我们不能启封测试集。
但是我们可以做的事将训练集切一小块出来,当作临时模拟卷来用。这就是 验证集 (Validation Set) 。通过这种方式我们就可以在不碰测试集的情况下评估模型是好是坏。
- 超参数调优 (Hyperparameter Optimization)
模型的参数是模型自己学出来的,例如回归线中的斜率和截距。而 超参数 (Hyperparameter) 是人为设定的学习配置。例如,我们要把数据分成几类?或者学习速率要有多块?
超参数调优就是不断调整这些人为配置,直到模型在验证集上表现良好。
当模型训练好了,我们就要进入评估与预测阶段了。这时候启封测试集:
我们在测试集上得出来的误差, 泛化误差 (Generalization Error) , 就被认为是模型在未来面对全新数据的真实表现。